OSPP2024 Proposal
图数据库 NebulaGraph 对接数据访问层 OpenDAL
申请人介绍
-
Github: feathercyc
-
邮箱:feathercyc@163.com
-
教育经历:
- 2023-现今:硕士,计算机科学与技术,华中科技大学
-
Rust 相关经历:
-
该项目使用 rust 语言重写 net-tools 的 arp 命令,涉及技术栈有:
- 使用
clap库模仿原 C 语言版的 arp 命令的命令行行为 - 使用
libc、nix库调用 Linux 系统调用 - 过程宏预处理 help 文档
- 使用
-
Xline 可简单看作 Rust 版 etcd,该 PR 解决了一个 good-first-issue,优化了 append entries 函数的行为,减少了时间复杂度。
-
该项目实现了一个高效率的、可用于异步运行时下的区间树供 Xline 项目调用,特点如下:
- 实现了红黑树完整的插入删除操作
- 使用数组模拟指针解决红黑树父子节点间需要相互引用的问题,因为使用常规的
Arc<>多使用权方法有严重的性能问题 - 详细、完整的注释以及 100% 的测试覆盖率
- 严谨的基准测试,最终性能为 etcd 使用的区间树 2 倍以上
-
-
OpenDAL 相关经历
修复了一处文档错误与一处
dev-container.sh脚本错误:
我对 Rust 非常非常感兴趣,我认为 Rust 脱胎于现代 C++ 但是比 C++ 更严格的语法规范有助于我写出更好的代码,加深我对软件工程的理解。我熟悉多种语言,在 Rust 身上能看到很多语言的身影,这让我感到非常的兴奋,我相信在掌握 Rust 的过程中我对其它语言的理解也会更加深刻。
同时我也对数据库领域相关技术很有兴趣,我独立完成了 CMU-15445、MIT 6.824 和 PingCAP 发起的 TinyKV 项目,对分布式数据库技术以及 SQL 执行引擎都有了一定程度上的了解,相信这点在我熟悉 NebulaGraph 以及 OpenDAL 的过程中会起到非常大的帮助。
项目介绍
相关 issue:
-
该 issue 提出希望为 OpenDAL 添加对 NebulaGraph 的支持以便用户可以通过 OpenDAL 访问 NebulaGraph 并存储数据。
使用方法会像这样:
1
2let op = Operator::via_map(Scheme::Nebula, map)?;
let bs = op.read("path/to/file").await?;
OpenDAL 简介
要给 OpenDAL 新增 Service,最低要求是为新增的 Service 实现位于 core/src/raw 下的 Access trait 和 Builder trait 。
而要新增 DB Service 则简单不少,因为 OpenDAL 定义了 Adapter trait,实现这个 trait 就可以让 OpenDAL 使用任何 KV 工作。因此,只要将各类 DB 的操作映射为 KV DB 的操作——set, get, delete, scan,OpenDAL 就可以使用这个 DB 了。
NebulaGraph 简介
Nebula Graph 是图数据库,其以 vertex,edge 和 tag 的形式存储数据。其中 vertex 为点,在一般项目中可以是一个人、一篇帖子、一个组织等任意实体;edge 则是点之间的关系,如引用、属于、包含等各种关系;而 tag 则是用来修饰 vertex 的东西,如个人信息,帖子发布信息,组织信息等。从 tag 的角度看,vertex 可以视作为一堆 tag 的集合。
图数据库这样做的优点在于灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱。它可以看作是特化了传统关系型数据库的 JOIN 操作,简化了用户查询实体之间的关系的操作,换言之,图数据库是比关系型数据库更注重关系的数据库。
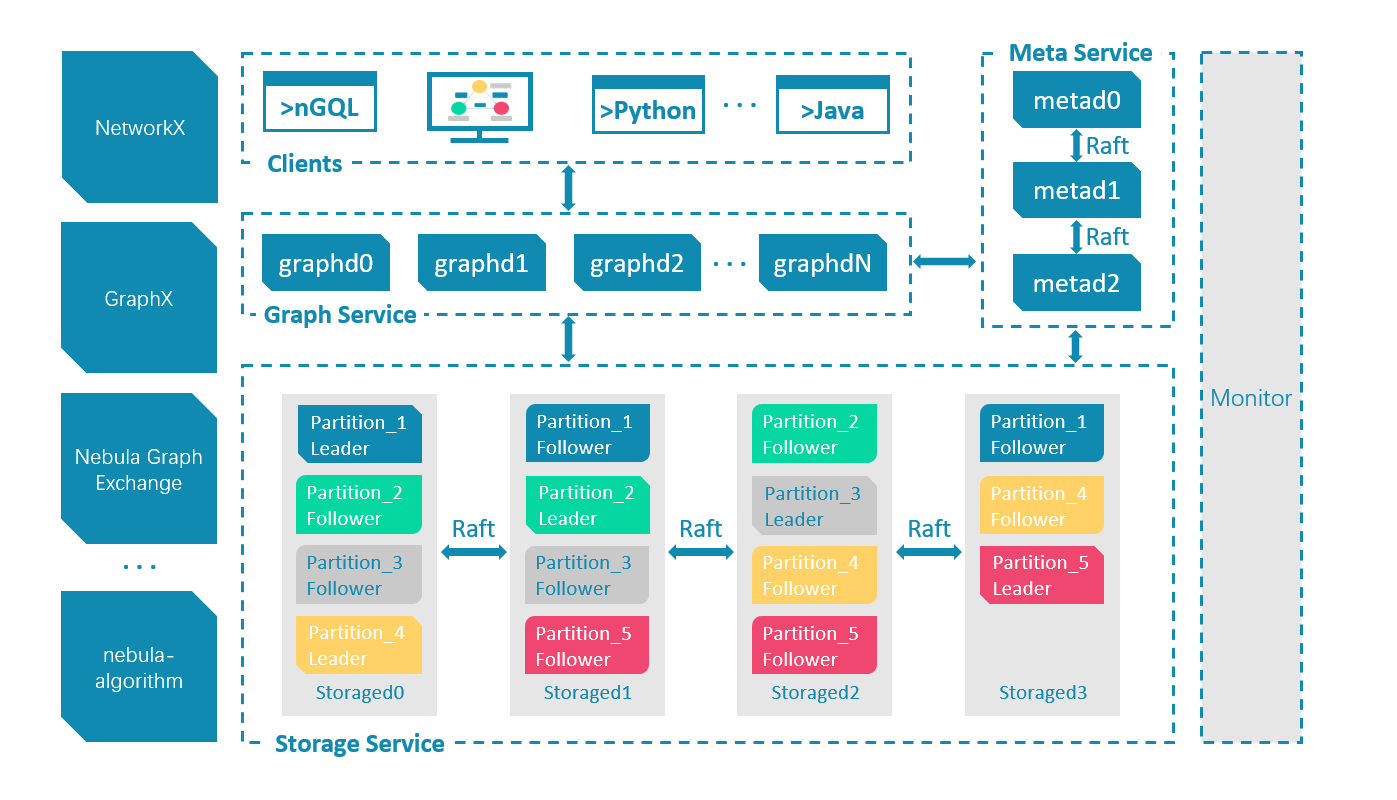
上图是官方的架构图,协议与周边生态细节略去不谈,易知 NebulaGraph 由三部分——graphd, metad, storaged 组成。其中 graphd 算是查询引擎,metad 存有服务地址和 Schema 等各类元信息,而 storaged 存储具体的数据。
graphd
NebulaGraph 结合 GQL 自研了 nGQL(nebula graph GQL)。正如各类 SQL 引擎所做的那样,graphd 负责将 nGQL 解析成对底层存储引擎相应的操作,算子合并、下推等优化操作也在这里进行,该部分与本任务关系不大。
metad 与 storaged
Nebula 的 Storage 包含两个部分,一是 meta 相关的存储,我们称之为 Meta Service,另一个是 data 相关的存储,我们称之为 Storage Service。这两个服务是两个独立的进程,数据也完全隔离,当然部署也是分别部署,不过两者整体架构相差不大。
https://www.nebula-graph.com.cn/posts/nebula-graph-storage-engine-overview
参考官方介绍,metad 与 storaged 在原理架构上并无太大区别,因此可以合并介绍,接下来只介绍 storaged。
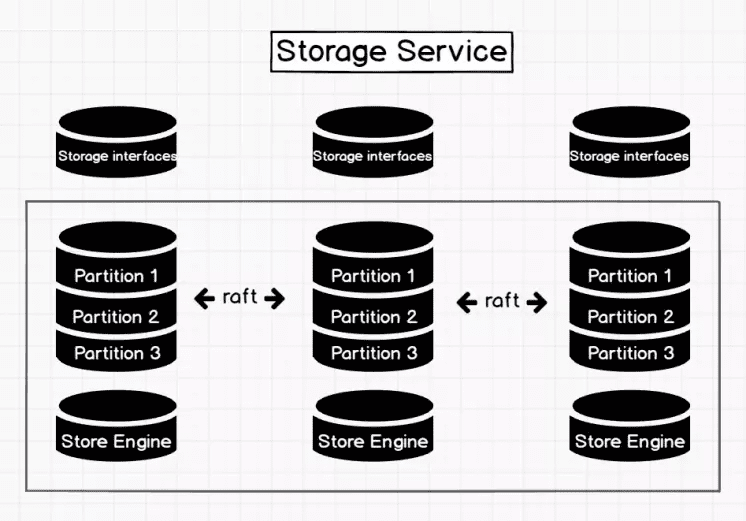
Storage interface 层
Storage 服务的最上层,定义了一系列和图相关的 API。API 请求会在这一层被翻译成一组针对分片的 KV 操作,例如:
- getNeighbors:查询一批点的出边或者入边,返回边以及对应的属性,并且支持条件过滤。
- insert vertex/edge:插入一条点或者边及其属性。
- getProps:获取一个点或者一条边的属性。
正是这一层的存在,使得 Storage 服务变成了真正的图存储,否则 Storage 服务只是一个 KV 存储服务。
https://docs.nebula-graph.com.cn/3.8.0/1.introduction/3.nebula-graph-architecture/4.storage-service/
同样参考官方介绍,storaged 为基于 RocksDB 的分布式存储服务,这点与 TiKV 很像。
Client 连接方式
既然 NebulaGraph 提供了 3 个独立部署的 server,那么 Client 直连 storaged 也应是可行的。官方提供了各种语言版本的 Client,其中 nebula-python 与 nebula-rust 都提供了该项功能。
使用 nebula-rust Client 连接 NebulaGraph 有两种方式可选:
- 使用 nGQL 操作 NebulaGraph。这是最简单的方法,这种方式先将带 nGQL 的请求发送给 graphd,然后由 graphd 去分别请求 metad 和 storaged 获取数据,再返回给用户
- 直连 storaged。考虑到一些简单的、大批量的操作并没有必要经过 graphd 这个中转站再传给 storaged 去做,用户也可以直连 storaged 获取 vertex 与 edge
这两种方法各有优劣:
- 使用 nGQL 操作固然方便,但要是 graphd 和 metad、storaged 不在一个服务器上,再简单的操作也要多出一段时延。
- 直连 storaged 固然能减少时延,但对于 NebulaGraph 用户而言,metad 与 storaged 很多时候都是不对外暴露服务的,参考 Should I use graphd-client or storaged-client?,而且 nGQL 能实现的各种基于图的算法肯定是用不了了
提案
OpenDAL
方案设计
方案 A
最简单的实现方案,由上可知只需将图数据库映射为 KV DB 就够了,只需按下列命令操作:
1 | // create test space, its vid type should be str |
同时参考 NebulaGraph 源码解读系列文章,可以知道 vertex 和 tag 属性在底层都是存在 RocksDB 中:
数据分片 Partition 或者有些系统叫 Shard,它的 ID 是怎么得到?非常简单,根据点的 ID 做 Hash,然后取模 partition 数量,就得到了 PartitionID。
Vertex 的 Key 是由 PartID + VID + TagID 三元组构成的,Value 里面存放的是属性(Property),这些属性是一系列 KV 对的序列化。
https://www.nebula-graph.com.cn/posts/nebula-graph-design-in-practice
虽然 NebulaGraph 会将 vertex 和 tag 存在两个地方,而不是像真正的 KV DB 一样存真正的 key-value 对,而且在存入之前还要经过 Raft 共识算法达成共识,性能相对于 RocksDB 一定有很多损失,但这是无法避免的事。
这样做的优势是显而易见的:
- 只插入 vertex,充分利用了 RocksDB,性能有保证
- 由于操作简单,在查询获取文件的时候可以直接访问 storaged 服务,省去通过 graphd 访问 storaged 的过程,性能会进一步提升
但这样做的缺点也是显然的:
- 由于 NebulaGraph 只能设置 VID 为固定长度字符串,要满足文件系统的需求则需要将这个固定长度设置为一个很大的数字(参考文件名最大长度 255),这将大幅度降低 NebulaGraph 的性能
create_dir可以理论上支持,但考虑第 2 点,即使约束文件名不超过 n (n<<255) 个字符,目录深度也会受到极大限制,而且处理 corner case 会很繁琐list不可能得到支持,因为使用了 vertex 的 VID 作为 key,但 nGQL 并没有提供 搜索 以 xxxx 为前缀 的 VID 的 vertex 的功能append,rename和copy操作性能会有问题,语义上实现这两个操作倒是简单,无非是先查再更新,但是性能肯定不佳,同时 nGQL 也不可能有原生的功能支持- 所以只能很好地支持
write,read,delete操作,就像 OpenDAL 现在绝大部分 DB 后端一样
方案 B
要将 DB 添加为 OpenDAL 的 Backend,本质上是使用这个 DB 去模拟一个文件系统树。众所周知树结构是图的子集,对于 NebulaGraph,其可以直接把文件树结构存进去而不需要任何额外的抽象。
首先需要创建一个合适的 space
- 创建测试用 space,为了解决 VID 作为文件绝对路径的性能问题,可以选择使用 INT 作为 VID,将真正的文件名存入 tag 中
1
CREATE SPACE test_fs(PARTITION_NUM = 20, VID_TYPE = INT);
- 创建文件类型 tag,分别为文件和文件夹
1
CREATE TAG file(name string, value string);
- 创建文件目录关系,这里没有什么其他需求,所以一个无属性 edge 就够了
1
CREATE EDGE child();
下面阐述该如何支持文件系统的各类操作:
write操作,以创建/test/init文件为例:- 首先要先判断
/test/是否存在1
MATCH (v:file{name:"/"})-->(v2:file{name:"test/"});
- 然后创建文件以及
init与/test/的关系,其中random_int和xxx's vid为伪代码1
2INSERT VERTEX file VALUES random_int:("init", "23");
INSERT EDGE child () VALUES test/'s vid -> init's vid :();
- 首先要先判断
create_dir操作,因为 OpenDAL 约定了test/为文件夹,而test为文件,所以其与write操作无区别read操作,以读取/test/init文件为例:1
MATCH (v:file{name:"/"})-->(v2:file{name:"test/"})-->(v3:file{name:"init"}) return v3;
delete操作,以删除/test/init文件为例:1
MATCH (v:file{name:"/"})-->(v2:file{name:"test/"})-->(v3:file{name:"init"}); | DELETE VERTEX $-.id WITH EDGE;
delete dir操作,以删除/test/文件夹为例:1
2// 那些在比 10 层更深目录里的文件和文件夹就删不掉了
GO 1 TO 10 STEPS FROM "/test/" OVER child YIELD dst(edge) AS id | DELETE VERTEX $-.id;list操作,以查看/test/文件夹为例:- 不递归查看
1
MATCH (v:file{name:"/"})-->(v2:file{name:"test/"}) RETURN v2 | GO FROM $-.id OVER child YIELD dst(edge) AS id;
- 递归查看
1
2// 那些在比 10 层更深目录里的文件和文件夹就不会展示了
MATCH (v:file{name:"/"})-->(v2:file{name:"test/"}) RETURN v2 | GO 1 TO 10 FROM $-.id OVER child YIELD dst(edge) AS id;
- 不递归查看
rename操作,以更改/test/init为/test/begin为例,其中的v3为伪代码:1
2MATCH (v:file{name:"/"})-->(v2:file{name:"test/"})-->(v3:file{name:"init"}) return v3;
UPDATE VERTEX ON file v3 SET name = "begin";append和copy操作受 nGQL 本身限制,与方案 A 一致,只能做到查询到点然后 UPDATE 或者 INSERT,在此略过不谈了。
方案 B 的优点如下:
- 完全地支持文件系统各类功能。因为图数据库完全适配文件树结构,甚至 OpenDAL 不支持的(软/硬)链接操作通过增加一个 edge type 理论上也能支持。
- 支持更深的文件目录层数以及更长的文件名。因为使用了 tag 来存文件名,以及 edge 来存文件与目录的关系,完全不需要担心 VID 过长的问题。
同时,他唯一的也是最显著的缺点就是性能不如方案 A。
这里的性能比较范围自然是指方案 A 支持的在根目录存取文件的操作,和支持了 create_dir 后,在没那么深的目录里存取文件的操作。方案 B 显然多了两步,它要先查询当前目录的 VID,插入文件的时候还要插入 edge。
而且由于这些操作比较复杂,使用直连 storaged 加速访问也变得不可能了。
方案 B 相对方案 A 做了两点改变:
- 存入了文件与目录之间的关系来实现
list操作 - 采用 tag 存文件名,避免设置一个很长的 VID 固定长度,还可以优化
rename操作
而这两点带来了两步额外操作:
- 存入了文件与目录之间的关系导致插入文件的时候还要插入 edge
- 采用 tag 存文件名导致每次操作都要先查询当前目录的 VID
那么自然,也有一个折中的方案。
方案 C
方案 C 的操作就很明了了:
- 存入文件与目录之间的关系
- 使用文件的绝对路径作为 VID
因为原理一样,这里的 nGQL 操作就略去不写。
方案总体评价
实际上对方案 A, B, C 的选择就是对功能与性能的取舍,在进行 benchmark test 前,我是更加倾向于选择方案 B 的,因为将文件树映射为图显然更富有挑战一些。
Nebula Graph 基于图数据库的特性使用 C++ 编写的 NebulaGraph,可以提供毫秒级查询。
https://docs.nebula-graph.com.cn/3.8.0/1.introduction/1.what-is-nebula-graph/
参考官方文档,NebulaGraph 提供的是毫秒级的查询,考虑即使是方案 A,提升的性能也不会太多,因为上限就在那。而且考虑到 OpenDAL 本身也支持了 RocksDB,这样隔着 NebulaGraph 访问 RocksDB 的行为可能显得有些意义不明。
而且我认为方案 B 在一些场景下有显著优势:
- NebulaGraph 作为网络服务提供,那么方案 A 多的那点性能在网络时延面前显得不值一提
- 必须要支持长文件名、很深的目录层数以及
list操作 - 性能不敏感场景,不需要高吞吐量的文件系统,那么自然文件系统功能越全越好
计划表
参照官方日程表,如果我被选中,我将在 07/01-09/30 期间进行开发:
| 星期 | 日期 | 预定工作 |
|---|---|---|
| 1-2 | 07/01 - 07/14 | 测试 Nebula rust 客户端 |
| 3 | 07/15 - 07/21 | 测试方案 A 的 nGQL 性能 |
| 4 | 07/22 - 07/28 | 测试方案 C 的 nGQL 性能 |
| 5-6 | 07/29 - 08/18 | 测试方案 B 的 nGQL 性能 |
| 7 | 08/19 - 08/25 | 为 OpenDAL 实现方案 A |
| 8 | 08/26 - 09/01 | 为 OpenDAL 实现方案 C |
| 9-10 | 09/02 - 09/15 | 为 OpenDAL 实现方案 B |
| 11 | 09/16 - 09/22 | 测试整体功能 |
| 12 | 09/23 - 09/30 | 写结项报告 |