Mysql 索引设计笔记
聚集索引
- 非聚集索引:也叫 Secondary Index。指的是叶子节点不按照索引的键值顺序存放,叶子节点存放索引键值以及对应的主键键值。
- 聚集索引:也称 Clustered Index。是指关系表记录的物理顺序与索引的逻辑顺序相同。由于一张表只能按照一种物理顺序存放,一张表最多也只能存在一个聚集索引。与非聚集索引相比,聚集索引有着更快的检索速度。
非聚集索引与聚集索引应当是要与 Innodb 引擎绑定的,从简易的 CMU15445 数据库以及 Miniob 数据库设计来看,最基本的索引应当是 key 是 col 的值,value 是数据库自己管理的 page index 以及 offset,这里的 value 也可称为行指针。同样的,MyISAM 引擎和简单的 memory 引擎用的都是这种行指针。
在很多地方能看到——MyISAM 引擎用的是非聚集索引——这种奇妙的话。按叶子节点存放索引键值以及对应的主键键值这一定义来看,这显然会导致一个问题——那么主键键值又该怎么访问呢?这句话仅仅考虑了非聚集索引叶子节点不按照索引的键值顺序存放的特点,未免有失偏颇。
MyISAM 这样设计的索引显然是会有好处的,或者说从最符合先把一个东西跑起来的工程角度来考虑,显然将新数据直接放在数据文件的末尾,然后返回相应的行指针是符合直觉的。这意味着这条数据只需在插入的时候更新索引即可,抛开删除这一操作不谈,其他数据的更改是断然不会影响这条数据的行指针的,也就不会导致更多的索引操作。
但是 MyISAM 这种设计也是有坏处的,即叶子节点不能按照索引的键值顺序存放。这对范围查询和磁盘的顺序访问极不友好。因此 Innodb 提出了聚集索引这一概念,这样关系表记录的物理顺序就将与索引的逻辑顺序相同,遍历的时候就可以一次性载入一整个磁盘页,甚至可以预载入后续的几个磁盘页。
故事说到这里,聚集索引与单纯的插入文件末尾这一操作的优缺点已经很明显了,不过说到底这也只是使用场景的不同,毕竟要想到 LSM-Tree 同样是不停的往文件末尾后面插数据,风头出的不比 B+ 树少。抛开可能存在的 MyISAM 与 Innodb 的代码质量差异问题不谈(笔者没有详细了解过两者的源码,但是显然理念正确,代码质量仍然能显著影响运行效率),至少可以看出来这两条路都是有自己的发展空间的,并无高低之分。只能说互联网的使用场景也是 Innodb 得到极大发展的一大重要因素。
回表
但是大家都知道 Innodb 还有个独属于它的操作——回表,即从二级索引(非聚集索引)中先查出主键值,然后再返回聚集索引查询真正的数据行。
首先是为什么回表操作是独属于 Innodb 呢?按前文所说,因为 MyISAM 的主索引和二级索引存的都是行指针,这显然是不需要回表的,无论访问什么索引,只需要访问到相应的节点了,那么就可以直接拿着指针获取所有数据了。
这里要提一嘴 Innodb 的聚集索引叶子节点结构,它有索引的特点,但更应该看作是一种数据本身的组织形式。因为聚集索引叶子节点的 key 是 col 的值(实际因为 MVCC,还有事务 id 和回滚指针),value 就是真正的数据行,聚集索引将直接管理数据在底层的排列方式,这一组织形式与回表操作是息息相关的。
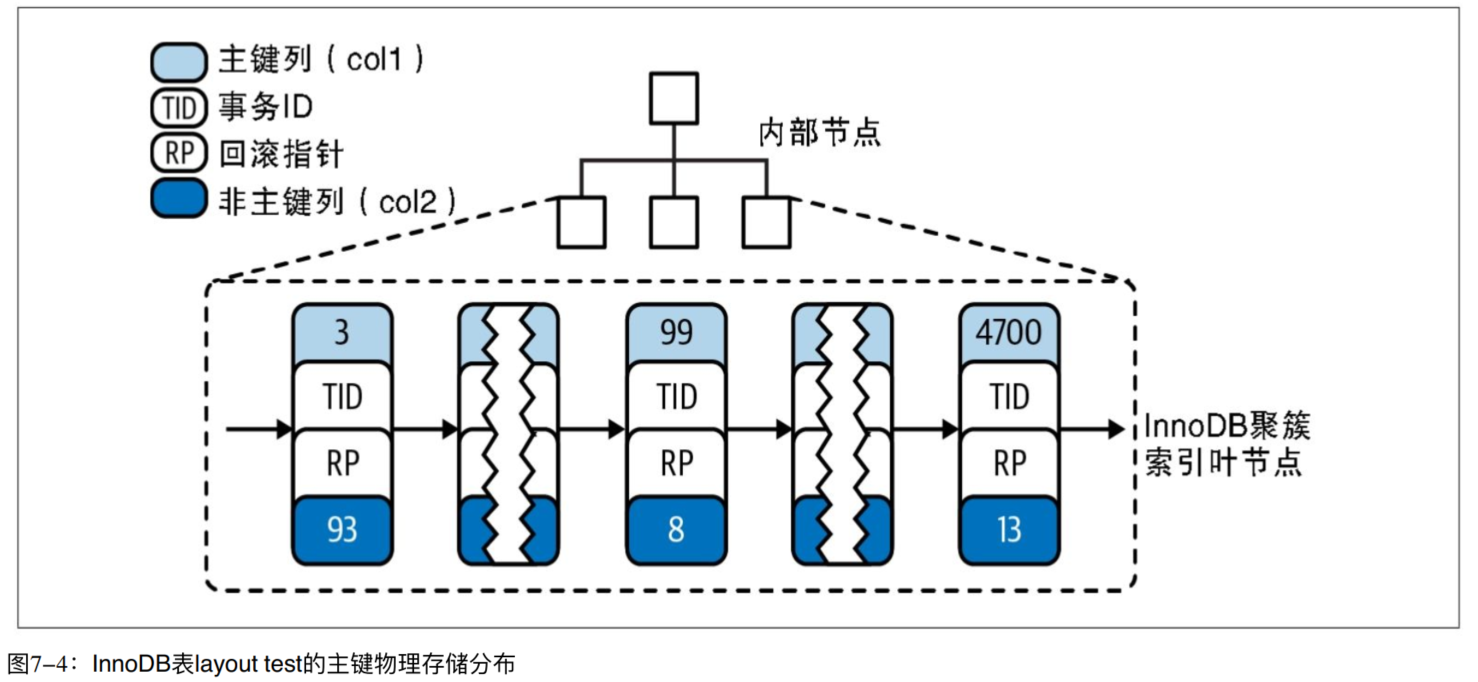
Innodb 的主索引存的是数据行,当然也可以是行指针,只不过没必要。但是为什么它的二级索引(也是非聚集索引)存的就是主索引的键值而不是行指针呢?答案是显而易见的,假如是行指针的话,好处是不需要回表了,坏处则是因为要进行按主键对数据进行排序操作,所以数据的行指针是会变动的,每次变动都要更新一遍所有的索引,这个代价似乎有些不可接受。考虑到回表这一操作怎么说也是在内存里进行的(从当今的互联网企业作风来看,几乎可以默认实践中的数据表主索引肯定是全部在内存里的,不然加钱就 OK),似乎每次查询多走一遍主索引也不是不能接受。
最左前缀匹配原则
一旦深入到数据底层排布方式,就能发现有很多查询似乎是可以走索引的,比如 (a, b) 的联合索引,只查询 b 的值,按所谓的最左前缀匹配原则,那肯定是不走联合索引的,但——凭什么呢?只要这个索引在内存里,再怎么说 b 不按顺序排不方便筛选,那也比全表查询快吧。
笔者在《高性能 Mysql(第四版)》中发现了这段话,马上就释怀了:

还有一张知乎答主截图:
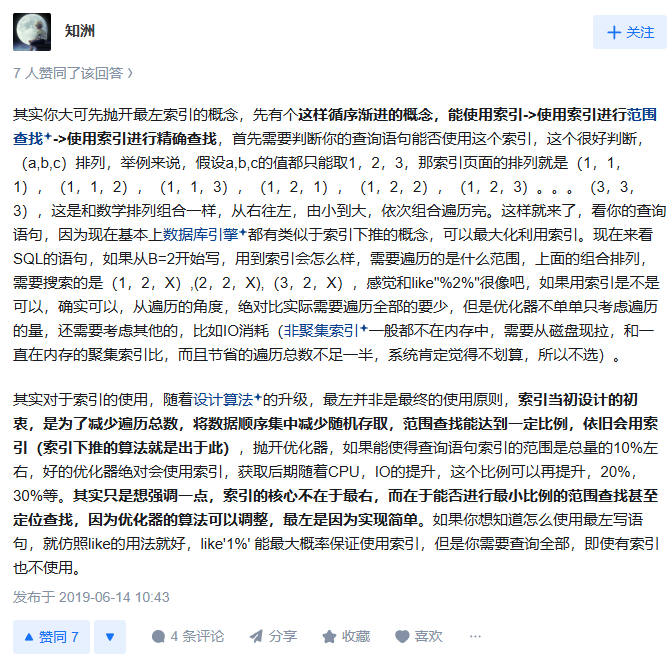
总之不可将最左前缀匹配原则当作铁律,说到底这应该是 Mysql 的设计者偷懒的锅(发表暴论)。