C 十十 面经杂文
STL,C++11
move 相关
这里需要构造一个方便指明不同对象的 class A,下面的实现是不符合复制、移动构造函数的语义的,请不要模仿:
1 |
|
会发生值复制以及创建临时对象的地方
列个表方便对比查看:
| class B 构造函数定义 | 运行代码 | 输出 |
|---|---|---|
| B(A a) : _a(a) {} | A aa; B b = B(aa); | Construct A; Copy A(0) to A(1); Copy A(1) to A(2); Destruct A(1); end; Destruct A(2); Destruct A(0); |
| B(A a) : _a(a) {} | A aa; B b = B(std::move(aa)); | Construct A; Move A(0) to A(1); Copy A(1) to A(2); Destruct A(1); end; Destruct A(2); Destruct A(-1); |
| B(A a) : _a(std::move(a)) {} | A aa; B b = B(std::move(aa)); | Construct A; Move A(0) to A(1); Move A(1) to A(2); Destruct A(-1); end; Destruct A(2); Destruct A(-1); |
| B(A& a) : _a(std::move(a)) {} | A aa; B b = B(aa); | Construct A; Move A(0) to A(1); end; Destruct A(1); Destruct A(-1); |
注意 end; 插入的时机,end; 是在 main 函数结束之前,B 构造之后输出,这里是方便看清函数参数值复制时临时对象的产生与消失过程。
1 | B(A a) : _a(a) {} |
这段函数显然发生了两处值复制,一个是 B(aa) 处的 aa 会复制成 B(A a) 这个参数 a,然后 _a(a) 则是正常的复制拷贝函数调用。
这两处地方都可以使用 std::move 语义,但是显然 move 的使用并没有让临时对象少生成,因为 move 仅仅是改变资源(成员变量)在变量间的所有权,在 aa 外面套一层 move 壳仅仅会将 aa 从 A& 标记为 A&&。换言之,B(A a) 这个函数创建临时对象的过程仍然存在,只不过 move 会让本该调用复制构造函数的临时对象改成调用移动构造函数(反正无论怎样还是要构造的)。
返回值优化(Named Return Value Optimization, NRVO)
返回值优化与临时对象是密切相关的,在栈上的对象并非是一定不可返回的,来梳理一下 C++ 返回值的过程,写一个测试函数如下:
1 | auto test_NRVO() -> A { |
这里需要禁用编译器的 NRVO
在没有 move 前(CPP98)函数会输出 Construct A; Copy A(10) to A(11); Destruct A(-1); end; Destruct A(11);,有了 move(CPP11 之后)编译器就已经会把复制构造函数替换成移动构造函数了,输出 Construct A; Move A(10) to A(11); Destruct A(-1); end; Destruct A(11);。
这说明了,test_NRVO 里的 aa 在不做 NRVO 前确实会消失,但 C++ 会先把这个 aa 赋值给函数外面的 a 再删除 aa。
反正 aa 最终都要删除,那么把 aa 变量所有权改成 a 而不是重新复制一份就是 move 语义带来的优化。而 NRVO 则更加激进,为什么一定要让 aa 消失呢?不如直接将 a 的内存地址改成 aa 就好,这时会输出 Construct A; end; Destruct A(10);。第二个优化会直接把第一个优化盖过去,所以可以看作时 move 优化的激进版。
因此要慎重考虑返回值的析构函数调用问题。 move 语义不影响临时对象的创建,但是 NRVO 会直接消除临时对象。
那么这是否意味着可以写出这样的函数呢:
1 | auto test_return_arr() -> int * { |
显然不行,因为 NRVO 只会对类类型进行优化,上面这个函数返回的指针指向的数组地址一定是被自动释放了,这是危险操作。但是这样可以:
1 | auto test_return_arr() { |
所以 C++11 之后都建议使用 std::array。
说实话,笔者认为在函数开头赋值一个类类型然后返回的写法也很危险,这种延续栈变量生命周期的编译器行为有些隐蔽了,万一出现什么 Bug,检查代码时也容易忽略。
右值引用
谈一下你对 &,const &, && 的理解
也可以从右值构造函数那道题跳过来
万能引用(Universal Reference)
完美转发(std::forward)
cast 操作符
C98 的产物,reinterpret_cast 和 const_cast 都相当于绕过 C 的类型检查,有良好的代码设计都不会建议使用。
dynamic_cast 的转化效率令人诟病。转换不安全或不可能的报错有:
- 对于指针它会返回 nullptr
- 而对于引用则抛出一个 std::bad_cast 异常
要使用 dynamic_cast 进行向下转型,基类通常需要至少有一个虚函数(即包含虚表 vtable),这是因为 RTTI 数据是存储在虚表中的。这意味着只有当基类拥有虚函数时,派生类才能被正确识别并支持 dynamic_cast。
| 转换操作符 | 主要用途 | 适用场景 |
|---|---|---|
static_cast |
基本类型的转换、具有继承关系的类之间进行的类型转换、去除 void*指针的具体化 | 用于基础数据类型的转换(如 int 到 float)、具有直接继承关系的类之间的转换;不提供运行时检查 |
dynamic_cast |
安全地处理多态类型的转换 | 用于向下转型(即将基类指针或引用转换为派生类指针或引用),提供运行时检查确保转换的安全性 |
reinterpret_cast |
进行低级别的类型转换,可能涉及将一种类型的数据重新解释为另一种类型 | 适用于需要绕过 C++ 类型系统的情况,比如实现某些特定算法或与硬件直接交互;使用时需非常小心,因为可能导致 UB |
const_cast |
添加或移除对象的常量属性 | 专门用于添加或移除引用的 const 或 volatile 属性,当引用或指针指向的变量本身是 const 时,该变量由于储存在某块只读内存区域,可能触发 UB |
类型擦除相关记录
智能指针相关
详情见智能指针之说。
std::function
因为其他语言函数指针实现的太好了以至于想象不到 std::funtion 的作用,记录如下:
1 |
|
由此可见 std::function 就是为了统一函数接口提出来的,由于是跟 lambda 函数、std::bind 一起提出来的,基本上可以看作是配套措施。rust 和 go 完全没有这种历史包袱,打一开始就是 lambda 函数和正常函数一样传。
lambda 函数不捕获变量也可以作为函数指针传入,但捕获变量了就不行(为什么呢,见lambda 函数与仿函数)。
而类的非静态成员函数都有个 this 指针作为第一个参数,即使用了 std::bind 绑定了 this 指针,std::bind 返回的可调用对象(可调用对象是 C11 对上述几种函数统一的称呼)也不能直接转成函数指针。那么在 C11 前该怎么传入类的非静态成员函数呢,使用适配器模式即可的:
代码实现
1 |
|
lambda 函数与仿函数
std::future 和 std::promise、std::packaged_task、std::async
需要注意的是 future 和 promise 是还是基于 thread 的,而非 coroutine。毕竟是 C11 就引入的,而 C20 才有 coroutine 呢。
先声明 promise 然后获取绑定的 future,把 promise 丢到另一个线程里去,promise.set_value 就可以通过 future.get 了。
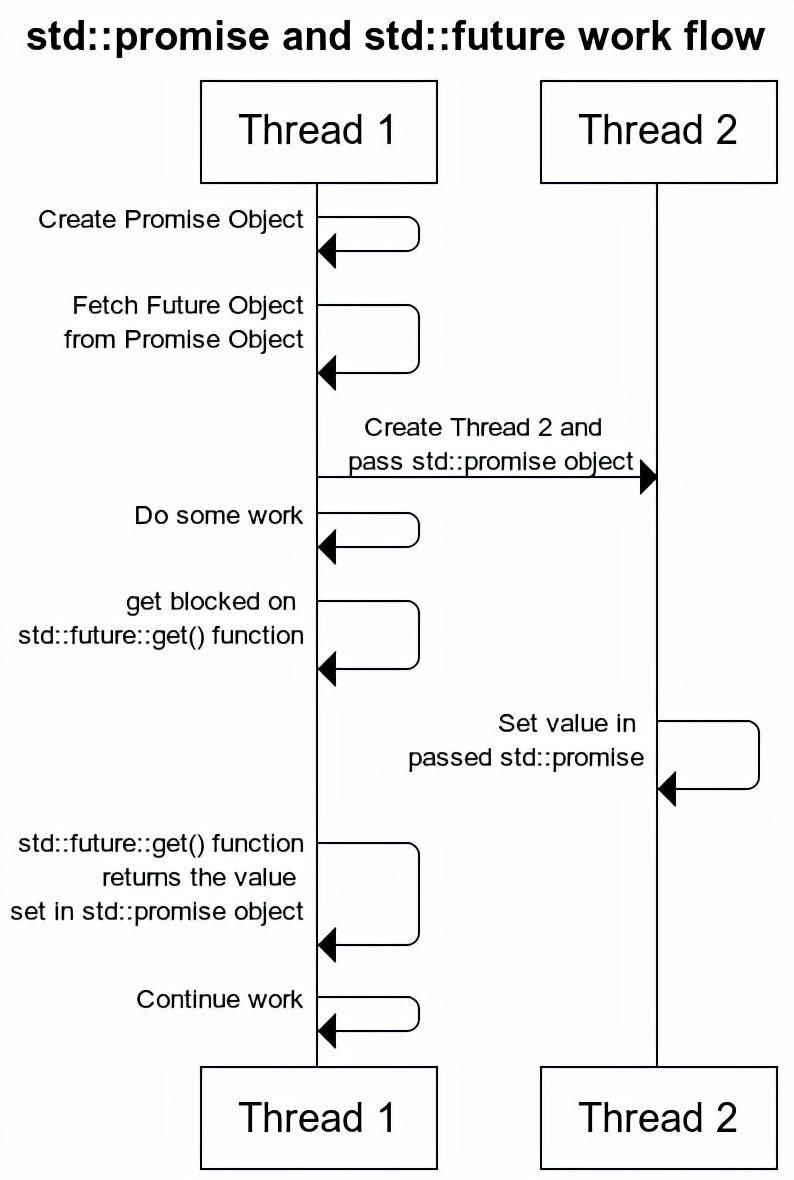
在 C++ 中,std::async、std::packaged_task 和 std::promise 都是用来处理异步任务和结果管理的工具,packaged_task 和 async 可以视作 promise 的高级封装(因为可以注意到大家都要搭配 future 用而不是搭配 promise 用)。
下面是对这三者的对比分析:
std::promise
1 | std::promise<int> promise; |
std::packaged_task
1 | std::packaged_task<int()> task([]() { |
std::async
1 | // 可以自动选择使用新线程(std::launch::async)或延迟执行(std::launch::deferred) |
对比总结
| 特性/工具 | std::promise |
std::packaged_task |
std::async |
|---|---|---|---|
| 启动异步任务 | 不直接启动任务,需配合其他机制 | 手动,需自行安排执行环境 | 自动,支持多种策略 |
| 资源管理 | 需要手动管理 | 需要手动管理 | 自动管理 |
| 使用便捷性 | 低(更灵活,但复杂) | 中 | 高 |
| 控制灵活性 | 最高 | 中等 | 较低 |
| 适用场景 | 复杂同步需求,多上下文设置结果 | 快速简单异步任务 | 需要更多控制的任务 |
STL 相关
STL 容器是分配在堆还是栈
各种容器对象本身通常是分配在栈上的,但是它管理的动态数组(即其元素)是存储在堆上的。
sizeof(vector) 返回的是 vector 对象大小还是容器大小
sizeof(vector) 返回的是该 vector 对象本身的大小,而不是它所管理的动态数组的大小。这个值通常包括几个指针或索引(如指向数据的指针、容量和大小等),因此它是一个相对较小且固定的数值。
vector 的 clear() 的时间复杂度是多少?
抛开 POD 类型不谈,考虑到每个元素都需要做析构操作,实际复杂度会是 O(N)。
怎么在 vector 变量的有效期内,释放其中元素所占的内存?
这里我直接说一下答案。
1 | vector<Data>().swap(v); |
如果对方能正确写出,可以继续追问。如下写法是否也能达到目的?为什么?
1 | v.swap(vector<Data>()); |
答案是不能。因为 swap 的参数是 T&,不能传递匿名对象。
C++ 的 emplace_back 能完全代替 push_back 吗?
vector
- resize:改变容器大小。如果新尺寸大于当前尺寸,则使用默认值或提供的值填充新增空间;如果小于当前尺寸,则删除多余的元素。
- reserve:请求容器分配足够的存储空间来容纳至少指定数量的元素,但不会改变容器的实际大小。这有助于减少内存重新分配的次数。
deque
deque 通常作为一组独立区块,第一区块朝某方向扩展,最后一个区块朝另一个方向扩展。
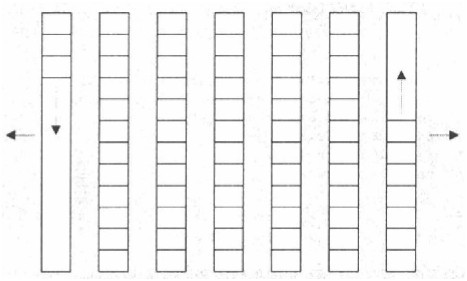
- resize:类似于
vector的resize,但是由于deque的内部结构不同(块状连续存储),其性能特征也有所不同。
unordered_set / unordered_map
- rehash:调整容器的桶数,通常用于提高哈希表的性能。它强制容器重建其哈希表,可能导致所有元素的重定位。
- load_factor:获取或设置容器的负载因子,即每个桶的平均元素数。较高的负载因子可能导致更多的碰撞和降低查找性能。
插入一个元素后迭代器的有效性
| 容器名称 | 插入后的迭代器有效性 | 理由 |
|---|---|---|
list/forward_list |
迭代器不会失效。 | list是双向链表,forward_list是单向链表,它们节点独立存在,插入新节点不会影响其他节点的位置或迭代器的有效性。 |
set/map |
迭代器不会失效。 | 因为它们通常基于平衡二叉树实现,插入新元素仅会改变树的结构,而不会使现有迭代器失效。 |
vector/string |
如果容器内存被重新分配,则所有迭代器都失效,否则插入位置之后的迭代器都会失效。 | 因为vector的底层实现是连续存储空间,插入可能导致内存重新分配,从而使迭代器失效。 |
deque(首尾两端的变化存疑) |
增加任何元素都将使 deque 的迭代器失效,但两端插入时指针、引用仍有效。deque 是唯一一个在迭代器失效时不会使它的指针和引用失效的标准 STL 容器。 | deque支持两端快速插入。 |
unordered_set/unordered_map |
在没有发生 rehash 的情况下迭代器不会失效;如果发生了 rehash,则所有迭代器都将失效。 | 当哈希表达到负载因子阈值时会发生 rehash,这会导致存储地址的变化,从而使得所有迭代器失效。 |
删除一个元素后迭代器的有效性
| 容器名称 | 删除后的迭代器有效性 | 理由 |
|---|---|---|
list/forward_list |
只会使被删除元素迭代器失效。 | list是双向链表,forward_list是单向链表,它们节点独立存在,删除新节点不会影响其他节点的位置或迭代器的有效性。 |
set/map |
只会使被删除元素迭代器失效。 | 因为它们通常基于平衡二叉树实现,删除新元素仅会改变树的结构,而不会使现有迭代器失效。 |
vector/string |
被删除元素之后的迭代器都会失效。 | 因为vector的底层实现是连续存储空间,删除不会导致内存重新分配。 |
deque(首尾两端的变化存疑) |
在 deque 的中间删除元素将使迭代器、指针、引用失效,而在头或尾删除元素时,只有指向该元素的迭代器失效。deque 是唯一一个在迭代器失效时可能不会使它的指针和引用失效的标准 STL 容器。 | deque支持两端快速删除。 |
unordered_set/unordered_map |
只会使被删除元素迭代器失效。 |
如何高效删除 C++ vector 中所有下标为偶数的元素?
模板函数
类模板全特化与偏特化
代码实现
1 |
|
函数模板特化
- 函数模板只有特化,没有偏特化(函数模板偏特化等价于新的一个模板函数,故没有偏特化的说法);
- 模板、模板的特化和模板的偏特化都存在的情况下,编译器在编译阶段进行匹配,优先特殊的;
- 模板函数不能是虚函数;因为每个包含虚函数的类具有一个 virtual table,包含该类的所有虚函数的地址,因此 vtable 的大小是确定的。模板只有被使用时才会被实例化,将其声明为虚函数会使 vtable 的大小不确定。所以,成员函数模板不能为虚函数。
面向对象
构造函数
只有构造函数可以重载,其他的默认函数(复制构造、移动构造和析构函数)都有唯一的函数签名,不可重载。
初始化列表
explicit 关键字
指定构造函数或转换函数(C++11 起)为显式,即它不能用于隐式转换和复制初始化。
explicit 关键字只对有一个参数的类构造函数有效,如果类构造函数参数大于或等于两个时,是不会产生隐式转换的,所以 explicit 关键字也就无效了。
但是,也有一个例外,就是当除了第一个参数以外的其他参数都有默认值的时候(每个参数都有默认值也可以的,如下例,核心要点在于是否可以触发隐式转换),explicit 关键字依然有效,此时,当调用构造函数时只传入一个参数,等效于只有一个参数的类构造函数。
1 | class Point { |
上述 Point p = 1; 会触发 Point(int x = 0, int y = 0) 这个构造函数的隐式调用,C++ 就是这样的自由。因此为了禁止这种行为可以使用 explicit 关键字如下:
1 | class Point { |
析构函数
只有析构函数可以为虚函数,其他的构造函数(构造函数、复制构造和移动构造)都不能为虚函数。因为虚函数表在构造函数之前并没有初始化好,类是不知道该去找哪个虚函数执行的。
复制构造函数
函数签名为
1 | T(T& t) |
对于复制构造函数,虽然其不能为虚函数,但是很容易可以实现一个虚函数 Clone() 实现相同效果:
1 | class BaseShape |
移动构造函数
函数签名为
1 | T(T&& t) |
= 操作符重载
操作重载会把复制构造和移动构造的逻辑重复一遍,但是考虑为方便链式调用,函数签名为:
1 | // 以移动构造为例 |
这里的返回参数写法与构造操作没有任何关系,不返回 *this 也完全不影响单个的 a=b; 赋值式子,主要是方便链式调用。
a = b = c; 的调用顺序
视作 a = (b = c); ,也就是 b 调用 = 操作符复制了 c,然后返回了 b(*this 就是 b 本身),a 再调用 = 操作符复制 b。
菱形继承
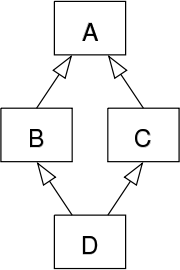
使用 class B: virtual public A 这个虚继承语法使得 A 在任意派生类中只存一份,由此解决。
虚继承通常涉及到一个额外的开销,因为编译器需要维护虚基类的信息,以确保在运行时可以正确地构造和定位虚基类的实例。因此,只有在需要解决菱形问题时才应该使用虚继承。
因为支持多继承,引入了菱形继承问题,又因为要解决菱形继承问题,引入了虚继承。而经过分析,人们发现我们其实真正想要使用多继承的情况并不多。
所以,在 Java 中,不允许“声明多继承”,即一个类不允许继承多个父类。但是 Java 允许“实现多继承”,即一个类可以实现多个接口,一个接口也可以继承多个父接口。由于接口只允许有方法声明而不允许有方法实现(Java 8 之前),这就避免了 C++ 中多继承的歧义问题。
友元函数与友元类
友元函数
友元函数时可以直接访问类的私有成员或保护成员,它是定义在类外的普通函数,不属于任何类,但需要在类的定义中加以声明。
友元函数的声明格式如下:
1 | friend 类型 函数名(形参); |
一般用法即 std::swap 的实现:
1 | // 比如在 MyString 类里声明 swap 以交换 private 变量 data 和 len |
友元类
设 B 为 A 的友元类,则 A 的所有成员函数都是 B 的友元函数,B 可以访问 A 的保护成员和私有成员。
- 友元类的关系是单向的,因此
class A { friend class B; };并不会让 A 成为 B 的友元类; - 友元关系不能被继承;
- 友元关系不具有传递性。即 B 是 A 的友元,C 是 B 的友元,但 C 不一定是 A 的友元,需要看类中是否有相应的声明。
Golang 与 C++ 的区别
Go(通常称为 Golang)和 C++ 是两种不同的编程语言,它们在设计理念、使用场景以及实现方式上都有显著的区别:
-
内存管理:C++ 提供了对内存的细粒度控制,包括手动管理内存分配和释放(如通过
new和delete)。而 Go 采用垃圾回收机制自动管理内存,简化了程序员的工作负担。 -
并发模型:Go 内置支持轻量级线程(goroutines),并通过通道(channels)来简化并发编程。相比之下,C++ 需要借助标准库或第三方库来实现类似的并发功能,代码通常更加复杂。
-
编译速度与效率:Go 设计之初就考虑到了快速编译,其编译速度通常比 C++ 快很多。这使得开发迭代过程更快。
-
面向对象编程:虽然 Go 支持一些面向对象的概念,但没有传统意义上的类和继承层次。C++ 提供了完整的面向对象编程支持,包括类、继承、多态等特性。
Go 的“轻量”体现在什么地方?
-
Goroutines:Go 的 goroutines 比传统的线程更加轻量,占用更少的系统资源,允许轻松创建成千上万的并发任务。
-
快速编译:Go 编译速度快,有助于提高开发效率。
-
简单易用的标准库:Go 提供了一个强大且易于使用的标准库,许多常见的编程任务可以直接利用这些库来完成,无需引入额外的依赖。
Go 的劣势在哪?
尽管 Go 有许多优点,但它也存在一些限制和不足之处:
- 性能优化难度:对于某些需要极致性能的应用场景,Go 可能不如 C++ 灵活,尤其是在需要精细控制硬件资源时。