raft 面经(?
按理说,做完了 6.824 理应对 Raft 了如指掌,可那是 11 个月前了,如今的笔者只能依稀记起来 lab 中印象较深的几个坑(其实也记不太清了。
所以可证明,做完 lab 面经全会。
为了让面试官不阴阳怪气\委婉\盛气凌人地跟笔者说——同学,你的项目是有借鉴 Github 吗?——记录一下笔者从各大网站搜罗而来的 Raft 协议面经。
CAP 是什么?Raft 实现了 CAP 中的哪两个
CAP(Consistency, Availability, Partition tolerance)。CA 只有单机实现,毕竟分布式系统必须有 Partition tolerance。

- 弱一致性——最终一致性(无法实时获取最新更新的数据,但是一段时间过后,数据是一致的)
- Gossip(Cassandra,Redis 的通信协议)
- 优先保证 AP 的 CouchDB,Cassandra,DynamoDB,Riak(一个都不了解)
- 强一致性
- Paxos
- Raft
- ZAB
还有 Quorum NWR 算法,根据 N、W、R 参数不同有强一致性或者最终一致性的效果。
据 PingCAP 所分享:
一些常见的误解:使用了 Raft 或者 paxos 的系统都是线性一致的(Linearizability,即强一致),其实不然,共识算法只能提供基础,要实现线性一致还需要在算法之上做出更多的努力。以 TiKV 为例,它的共识算法是 Raft,在 Raft 的保证下,TiKV 提供了满足线性一致性的服务。
笔者猜测一下 PingCAP 的意思,Raft 没想好,但是 Quorum NWR 在 W+R>N 的情况下,比如 N=5,写 3 个读 3 个,能确保读出来 [V1,V1,V2] 这种组合,V1 和 V2 肯定有一个是最新的,那么还需要接着读直到有一个的数量超过 2 个,理论上是这样。
假如这时混入了 V3 这个值,V1 和 V2 的分布就不对了,单纯的算法就读不到超过 2 个的值,但这个事完全可以通过引入时间戳和 undo log 来解决,这与算法是没关系的。所以算法是基础,要实现线性一致还需要系统配合(?
Raft 和其他共识协议相比的优缺点
不会
Raft 过程
什么时候做日志压缩
这是 LSM-Tree 的内容,不会。
为什么 Raft 的 RPC 需要带上任期号,举例不带任期号导致的错误场景
如果 Raft 给一部分节点发送数据操作的过程中突然宕机了怎么办?
超时重选
Raft 优化
prevote 阶段
no-op 解决 figure 8
ReadIndex
prevote
少于半数的 Follower 和 Candidate 陷入分区意味着 RequestVote 和 AppendEntries RPC 将失败。Raft 会无限期的重试,直到服务器重新启动。这时该分区的任期号将不断递增,最终合并分区时将导致新一轮的选举,这轮选举是不必要的。
no-op
Commit 限制:仅提交 leader 当前 term 的日志条目。
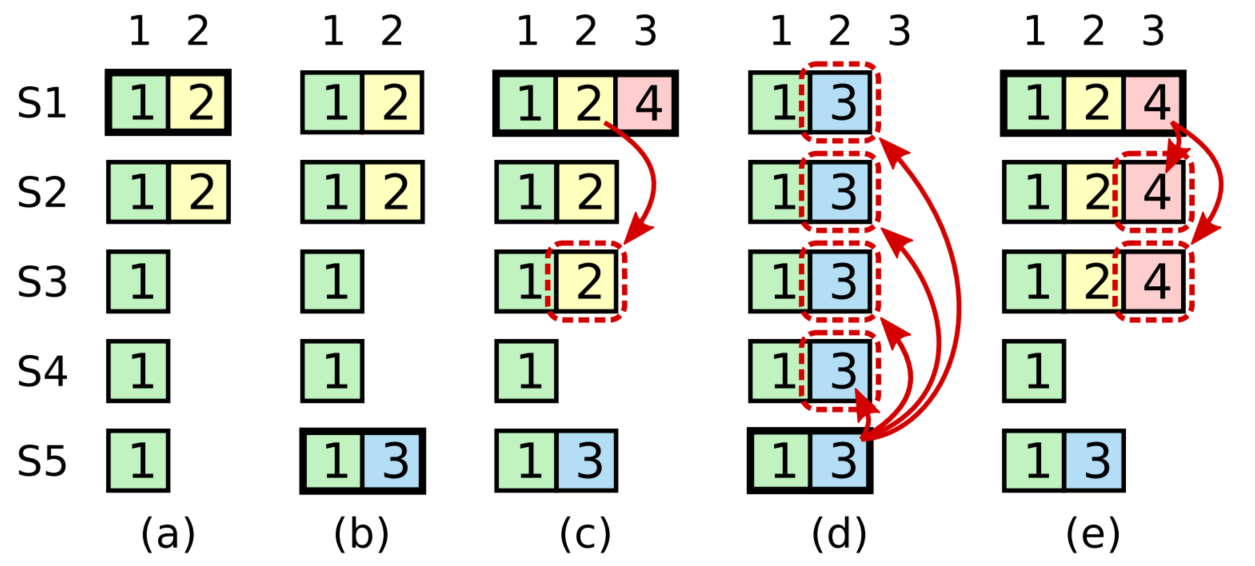
为什么要增加这个限制?我们同样基于这个图进行场景模拟就知道了。
- 阶段(a):S1 是 leader,收到请求后仅复制 index2 的日志给了 S2,尚未复制给 S3 ~ S5;
- 阶段(b):S1 崩溃,S5 凭借 S3、S4 和自身的投票当选为 term3 的 leader,收到请求后保存了与 index2 不同的条目(term3),此时尚未复制给其他节点;
- 阶段(c):S5 崩溃,S1 重新启动,当选为新任 leader(term4),并继续复制,将 term2, index2 复制给了 S3。这个时候 term2,index2 已经的日志条目已复制到大多数的服务器上,但是还没提交。
- 阶段(d):如果 S1 如 d 阶段所示,又崩溃了,S5 重新当选了 leader(获得 S2、S3、S4 的选票)然后将 term3, index2 的条目赋值给了所有的节点并 commit。那这个时候,已经 committed 的 term2, index2 被 term3, index2 覆盖了。
因此,为了避免上述情况,commit 需要增加一个额外的限制:仅 commit leader 当前 term 的日志条目。
如图,在 c 阶段,即使 term4 的时候 S1 已经把 term2, index2 复制给了大多数节点,但是它也不能直接将其 commit,必须等待 term4 的日志并成功复制后一起 commit。
所以除非说阶段 c 中 term2, index2 始终没有被 commit,这样 S5 在阶段 d 将其覆盖就是安全的,在要么就是像阶段 e 一样,term2, index2 跟 term4, index3 一起被 commit,这样 S5 根本就无法当选 leader,因为大多数节点的日志都比它新,也就不存在前边的问题了。
ReadIndex
Raft 集群发生网络分区会怎么样
Raft 成员变更
- 要么一次性严格限制只变更一个节点。
- 如果实在想一次变更多个节点,那就不能直接变更,需要经过一个中间状态的过渡之后才能完成同时变更多个节点的操作。第一次从 C_Old 变成{C_Old,C_New}节点集合,第二次从{C_Old,C_New}变成 C_New。
Raft 具体实现(比如 etcd)有哪些值得借鉴的
如果有多个节点竞选 Leader 怎么办?
Raft leader 选举过程
分布式系统中如果有多个分区,每个分区都有一个 Leader,现在将分区合并有多个 Leader 如何处理?
怎么区分 Leader 分别属于第几轮选举的?(Leader 选取的轮次计数)
Raft 算法中如果 Leader 宕机后怎么办?
如果 Raft 集群超过半数节点挂了会怎么样
上层业务如何使用 Raft?(面试官想的是和 etcd 那样单独作为一个存储服务
Raft 如何高可用
KV 存储如何容错
multi-Raft 实现
multi-Raft 怎么分片,分片怎么迁移
multi-Raft 原理(用哈希分片好吗?)
TiDB 的架构
项目的性能怎么样?最难的是什么?
Percolator 原理
一致性 Hash 算法是什么?为什么需要一致性 Hash 算法?
对于分布式缓存来说,当一个节点接收到请求,如果该节点并没有存储缓存值,那么它面临的难题是,从谁那获取数据?自己,还是节点 1, 2, 3, 4… 。假设包括自己在内一共有 10 个节点,当一个节点接收到请求时,随机选择一个节点,由该节点从数据源获取数据。
那有什么办法,对于给定的 key,每一次都选择同一个节点呢?使用 hash 算法也能够做到这一点。那把 key 的每一个字符的 ASCII 码加起来,再除以 10 取余数可以吗?当然可以,这可以认为是自定义的 hash 算法。
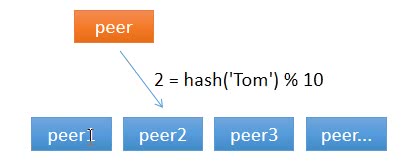
简单求取 Hash 值解决了缓存性能的问题,但是没有考虑节点数量变化的场景。假设移除了 10 个节点其中一台节点,只剩下 9 个,那么之前 hash(key) % 10 变成了 hash(key) % 9,也就意味着几乎缓存值对应的节点都发生了改变。即几乎所有的缓存值都失效了。节点在接收到对应的请求时,均需要重新去数据源获取数据,容易引起 缓存雪崩。
一致性哈希算法将 key 映射到 2^32 的空间中,将这个数字首尾相连,形成一个环。
- 计算节点/机器 (通常使用节点的名称、编号和 IP 地址) 的哈希值,放置在环上。
- 计算 key 的哈希值,放置在环上,顺时针寻找到的第一个节点,就是应选取的节点/机器。
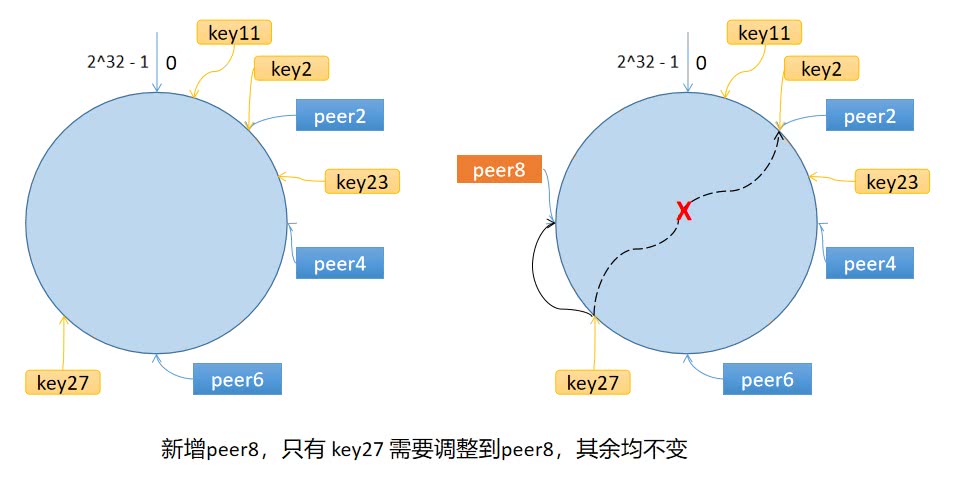
环上有 peer2,peer4,peer6 三个节点,key11,key2,key27 均映射到 peer2,key23 映射到 peer4。此时,如果新增节点/机器 peer8,假设它新增位置如图所示,那么只有 key27 从 peer2 调整到 peer8,其余的映射均没有发生改变。
也就是说,一致性哈希算法,在新增/删除节点时,只需要重新定位该节点附近的一小部分数据,而不需要重新定位所有的节点,这就解决了上述的问题。
一致性 Hash 的缺点是什么?
数据不平衡——虚拟节点解决