Mysql 锁机制笔记
行级锁与表级锁
行级锁由存储引擎实现,而表级锁则是服务器端实现。所以不同的存储引擎有不同的行级锁(说到底似乎只有 Innodb 有这个锁),但带伙的表级锁则是共用的。
网上存在大量博客在解说表级锁的时候每一句都要强调这个功能 Innodb 有,MyISAM 也有,这不是废话吗。。
间隙锁、记录锁与 next-key 锁
间隙锁锁开区间,记录锁锁单条记录,next-key 锁是两个锁组合锁 区间的。
间隙锁一副可以使用区间树的模样,但是考虑到只能锁两条存在记录的区间这一表现,比如有 id 为 2 和 10 的记录,现在查找 id<6 的记录,间隙锁按理说是,但实际上会锁。因此这是有原因的:
插入语句在插入一条记录之前,需要先定位到该记录在 B+ 树 的位置,如果插入的位置的下一条记录的索引上有间隙锁,才会发生阻塞。
https://xiaolincoding.com/mysql/lock/how_to_lock.html#非唯一索引等值查询
这就不奇怪了,毕竟复用了 B+ 树。
间隙锁与记录锁的行为感觉很容易死锁,尤其是二级索引加间隙锁的时候难以对主键索引加间隙锁,毕竟只能锁二级索引有序的键,主键上的二级索引值又不一定有序,这应该会导致主键索引能插入但是二级索引插不了的情况吧,虽然回退也能解决问题。
隔离级别
Mysql 有四个隔离级别,应当这样说明:
| 隔离级别 | 特点 | 实现思路 |
|---|---|---|
| Read Uncommited(读未提交) | 《高性能 Mysql》自己说的就算改成 RU 级别也不能让数据库变快多少,所以废物一个路边一条,无需在意 | 把数据库写出来就默认是这个状态 |
| Read Commited(读已提交) | RC 相较于 RU 主要是不至于会读到无效的、回滚的、不清楚来源的数据了,脏读被解决了。但参考实现思路,这种当然不能保证事务全程读到的数据是一致的。一个简单的场景,A 事务先读了一下 col a,A 还没结束时,B 事务以迅雷不及掩耳之势改好了 col a,标志位自然是先被标记然后又复原,A 事务再次读 col a 就没办法了,两次读的就不一致了。这就是不可重复读。 | 只需加个标志位,所有事务正在改的行设置一下,看到别人在改自己就不动就 ok。 |
| Repeatable Read(可重复读) | RR 诚如名字所说,终于保证了事务全程读到的数据是一致的,真是不容易。但显然这里还有一个更难解决的问题,这个问题就是幻读,幻读其实也属于事务全程读到的数据是不一致的子情况,事务 ID 这个方案是完全可以处理的。但这个问题难就难在为了运行效率,Mysql 只会在 select 语句使用事务 ID 这个机制,也就是快照读,而其他的语句在检查键值合法性的时候是不会使用事务 ID 的,也就是俗称的当前读,不使用那当然又会陷入 RC 的境地了。 | 引入事务 ID,同时还有配套的 Undo Log 就行,毕竟 true/false 不能看出是否被改动,但是一个自增的数字 id 肯定能。 |
| Serialize(串行化) | 串行化没什么好说的,分布式系统的最终目标也就是这个了 | 一把大表锁加上,何愁不能串行化,这是悲观锁。也可以先假设不会出现写偏斜这些问题,提交的时候再验证,这是乐观锁。SQL 本身也有 SELECT … FOR UPDATE 这种语法,在读的时候直接锁上所有的读过的行也是一种方法,这样的粒度也比一把大表锁小些。 |
笔者参考了 Miniob 的 MVCC 实现思路对 Mysql 的四种隔离级别重新进行梳理。
笔者向来推崇以消融实验的手法回顾知识点,某些效果一定是由某些新引入的机制导致的,现在看来很是不错(所以其实 RC 也不一定要靠加标志位来实现,反正 Miniob 是这么干的)。
2022 CMU 15445 则是使用表级锁管理器(不然 undo log 和间隙锁一个都没有是不可能防止幻读的)和事务 id 一次性实现了 RR,然后放松一些锁管理器就可以实现 RC 和 RU 了。Miniob 的标志位只是理论上能实现 RC,它并没有处理死锁的能力,所以要给 Miniob 实现 MVCC 道阻且长,还好比赛压根不要求实现。
如上文所说,RR 由于这个当前读的存在还是真正没能解决幻读,实际上带伙可以发现,一旦全程使用快照读,似乎变得不是那么需要再生造一个行级锁的概念了,只需小小的给每行数据加个锁复制一下到 Undo Log 里去,难道这种锁也需要单独起一个名字吗(带伙都是生造名词的天才)?
Mysql 选择使用行级别的读写锁以及引入了 next-key(记录锁 + 间隙锁)解决这个幻读的问题。
Mysql 解决幻读的方式也是如解,锁的具体细节先不谈,Mysql 会视每个事务的第一次非 select 操作(即 insert、select … for update 等)为当前读,然后上行级锁。行级锁确实能解决当前读后面的幻读问题,但是当快照读发生在当前读前面时,毫无疑问仍然会出现幻读现象。
一个例子:当事务 A 更新了一条事务 B 插入的记录,那么事务 A 前后两次查询的记录条目就不一样了,所以就发生幻读。
二个例子:如果事务开启后,并没有执行当前读,而是先快照读,然后这期间如果其他事务插入了一条记录,那么事务后续使用当前读进行查询的时候,就会发现两次查询的记录条目就不一样了,所以就发生幻读。
例子详情见 MySQL 可重复读隔离级别,完全解决幻读了吗?
写偏斜(Write Skew)与丢失更新(Lost Updates)
由于面经基本只会谈到脏读、不可重复读与幻读,仿佛 RR 已经解决了所有问题,与串行化没有任何区别了,这当然是错误的。有这样两个场景,RR(同时也称作快照隔离(Snapshot Isolation, SI))级别无法与串行化保持一致——写偏斜(Write Skew)与丢失更新(Lost Updates)。
写偏斜
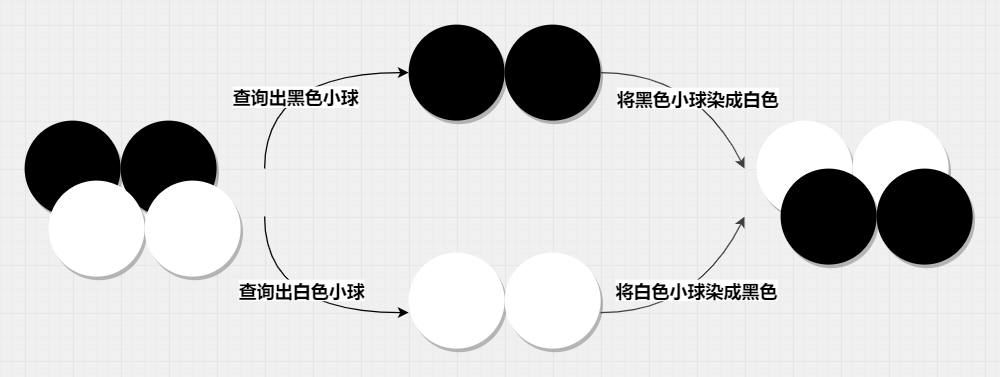
上图有两个事务,一个事务将白球染黑,一个事务将黑球染白。很容易发现,对于串行化而言,两个事务依次处理,最后的结果只可能是小球全部为黑或者全部为白。
但是 RR 并不保证这一点,两个事务在 2 黑 2 白的情况下读取了黑球集合与白球集合,然后做出了修改,最终结果仍为 2 黑 2 白,这是幻读或者脏读的一种吗?当然不是,读取的都是 commit 过的——不是脏读;即使事务 A 改成全黑并 commit,但事务 B 看到的仍然是 2 黑 2 白,不然也不可能将结果重新变成 2 黑 2 白——不是不可重复读;数据没有增加——不是幻读,但是结果就是和串行化的结果不一致,这就是写偏斜。
丢失更新

上图很清晰,不再解释。
丢失更新与写偏斜很相似,统称为写前提困境——也就是读出某些数据,作为另一些写入的前提条件,但是在提交前,读入的数据就已被别的事务修改并提交,这个事务并不知道,然后 commit 了自己的另一些写入,写前提在 commit 前就被修改,导致写入结果违反业务一致性。