如何假装自己是 GDB 糕手
GDB 是好的,笔者偶尔使用 GDB 调试大部分时间使用 Vscode/Clion 的按钮调试也是好的,只有说你平时用GDB吗?用IDE自带的?你基础不扎实啊。的面试官是坏的。
几句牢骚:抛开少数编译和启动时间就老长的大型项目不谈,校招生常见项目运行环境用个图形化界面怎么了?图形化界面本来每个按钮就和 gdb 命令一一对应,用熟了不是半斤八两?会个 gdb attach 就高贵了?
下面笔者尝试伪装自己平时对 vim 与 GDB 爱不释手,日常工作都是在没有图像化界面的 ArchLinux 上完成的,喜欢用萌萌哒语气,twitter 账号头像是粉蓝旗。
GDB 多线程调试小连招
| 命令 | 描述 | 示例 |
|---|---|---|
info threads |
查看所有线程及状态 | info threads |
thread <线程ID> / t <ID> |
切换到目标线程 | thread 3 |
thread apply all bt |
所有线程打印堆栈(排查死锁) | thread apply all bt |
set scheduler-locking on |
锁定当前线程,其他线程暂停 | set scheduler-locking on |
break <函数名> thread <ID> |
仅在指定线程生效的断点 | break critical_func thread 2 |
GDB 查看死锁原理
Linux 中的 mutex 结构体有着如下结构:
1 | struct __pthread_mutex_s |
假设 0x558b16eed0 是某个 mutex 的地址,在 gdb 中可以打印出前 3 个 4 字节变量:
1 | (gdb) x/3d 0x558b16eed0 |
如果像上面显示的那样全部为零,这意味着该互斥锁目前没有被锁定。这不是死锁。也许代码正在等待一个没有发生的条件。当另一个线程拥有互斥锁时,数据看起来可能像这样:
1 | (gdb) x/3d 0x558b16eed0 |
22022 是 thread identifier。不幸的是,gdb 不理解这个标识符,因此必须手动查找相应的线程号。例如使用 info thread 列出所有线程:
1 | (gdb) info thread |
这表示 thread 16 的 thread identifier 是 22022。
这样就可以知道哪个线程占有了这把锁,可以切换过去查看堆栈信息进一步确认问题。
GDB 查看死锁操作
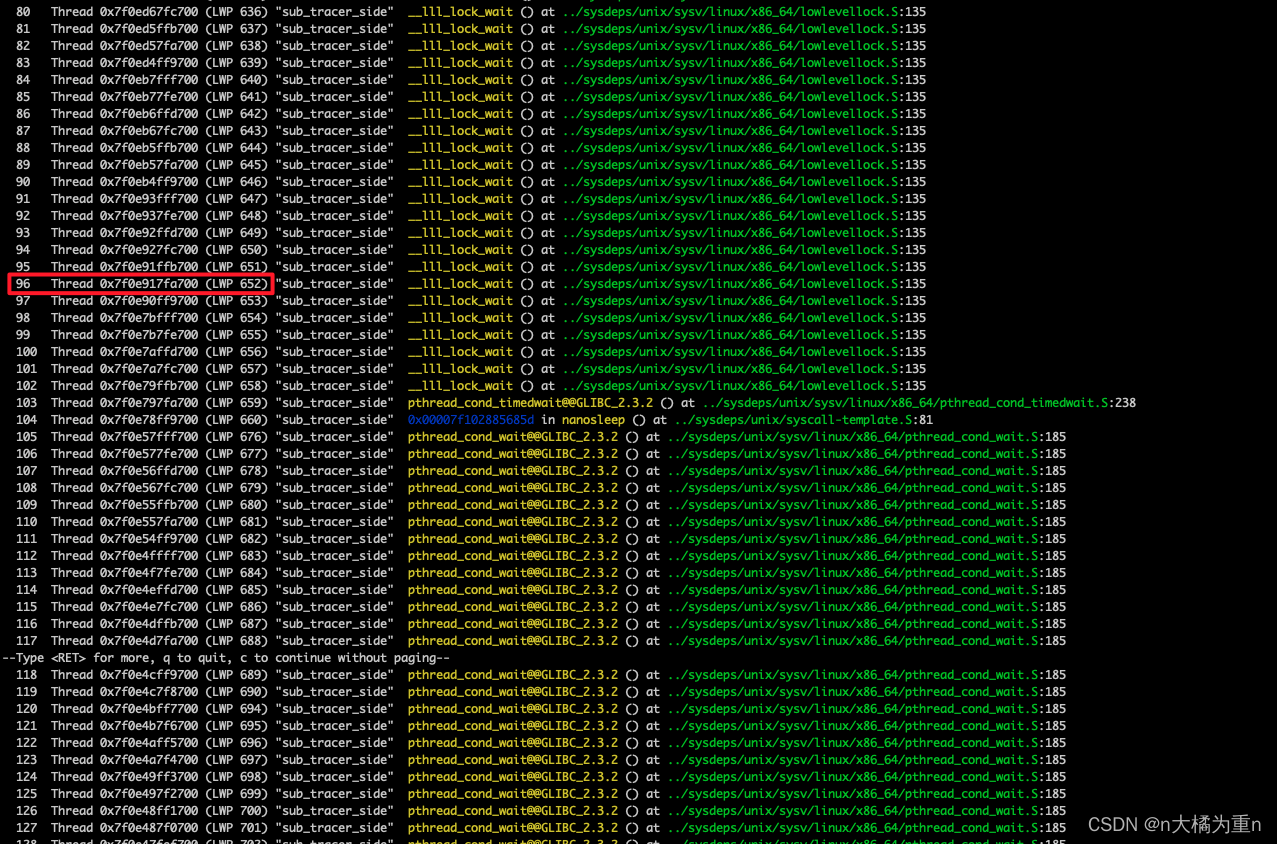
- 使用 info threads 查看所有的线程运行信息,例:
1 | (gdb) info threads |
- 发现有
__lll_lock_wait的即是正在等待锁释放,可以 thread n 进入某个子线程 - 比如进入到 4# 线程中,通过
bt查看当前线程的堆栈情况,可以看到锁是等在了 lock_guard 中,参考GDB 查看死锁原理,这里需要查看 os mutex 结构体的值,要先找到 mutex 变量的地址,可以通过看堆栈信息或者info args找到,然后通过x/3d [mutex address]打印锁的变量值:
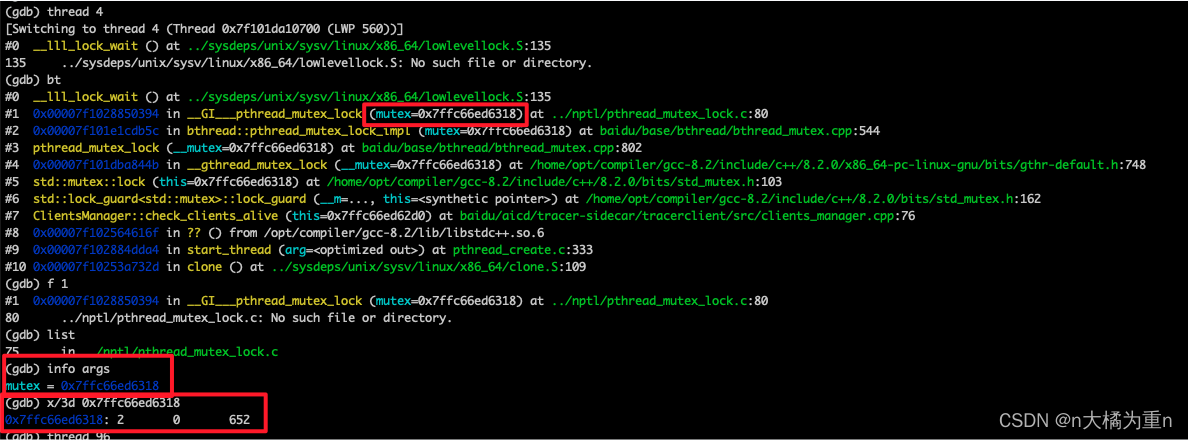
- 然后可以定位到是96#线程持有,还是上述的方法,thread 96,进入线程查看堆栈,然后结合代码分析线程是否存在互斥锁的范围、是否存在多个不同互斥锁的问题
参考文献
GDB 查看 Core Dump 小连招
| 命令 | 描述 | 示例 |
|---|---|---|
gdb [可执行文件] core |
加载 core 文件分析崩溃原因 | gdb my_program core |
为什么会有 Core Dump?
Linux 中信号是一种异步事件处理的机制,每种信号对应有其 Action,Action 主要包括
- Ingore(忽略该信号)
- Stop(暂停进程)
- Terminate(终止进程)
- Core(终止并发生 Core Dump)
- …
比如使用 Ctrl+z 来挂起一个进程会向进程发出 SIGTSTP 信号,该信号的 Action 为 Stop(暂停进程);使用 Ctrl+C 或者 kill -9 结束一个进程会向进程发出 SIGINT 信号,该信号默认操作为 Terminate(终止进程)。
以下列出几种信号,它们在发生时会产生 Core Dump:
| Signal | Action | Comment | Example |
|---|---|---|---|
| SIGQUIT | Core | Quit from keyboard | Ctrl+\ 中止程序 |
| SIGILL | Core | Illegal insturction | 加载了损坏的二进制代码、越界跳转等。 |
| SIGABRT | Core | Abort signal from abort() |
程序主动调用 abort() 函数触发,常用于断言失败(assert)等情况。 |
| SIGSEGV | Core | Invalid memory reference | Segmentation Fault |
| SIGTRAP | Core | Trace/Breakpoint trap | 用于调试器设置断点,当程序运行到断点时会收到此信号暂停执行。 |
分析 C++ 程序生成的 Core Dump 文件经常遇到的问题就是怎么打印出 STL 容器中的值以及 Boost 中容器的值
有如下三个工具可以高效的查看 STL 和 Boost 中容器的值:
内存泄漏检测
| 工具/命令 | 描述 | 示例 |
|---|---|---|
valgrind --tool=memcheck ... |
检测内存泄漏 | valgrind --leak-check=full ./a.out |
valgrind --tool=massif ... |
分析内存使用趋势 | valgrind --massif ./a.out |
内存泄露问题倒是难以使用 GDB 直接看出来,一般是辅以 AddressSanitizer(ASan)、Valgrind 这些工具查看的。
其中 Valgrind 通过运行时软件翻译二进制指令的执行获取相关的信息,所以 Valgrind 会非常大幅度的降低程序性能,这就导致在一些大型项目比如 Apache Doris 使用 Valgrind 定位内存问题效率会很低。
而 Sanitizer 则是通过编译时插入代码来捕获相关的信息,性能下降幅度比 Valgrind 小很多,使得能够在单测以及其它测试环境默认使用 Saintizer。
怎么查内存泄漏?(ASan 版)
编译器开启 -fsanitize=address 选项后直接运行程序即可,ASan 检测到错误会报错退出(也可以设置不退出)并打印出堆栈信息,堆栈信息长下面这个样子,不陌生:
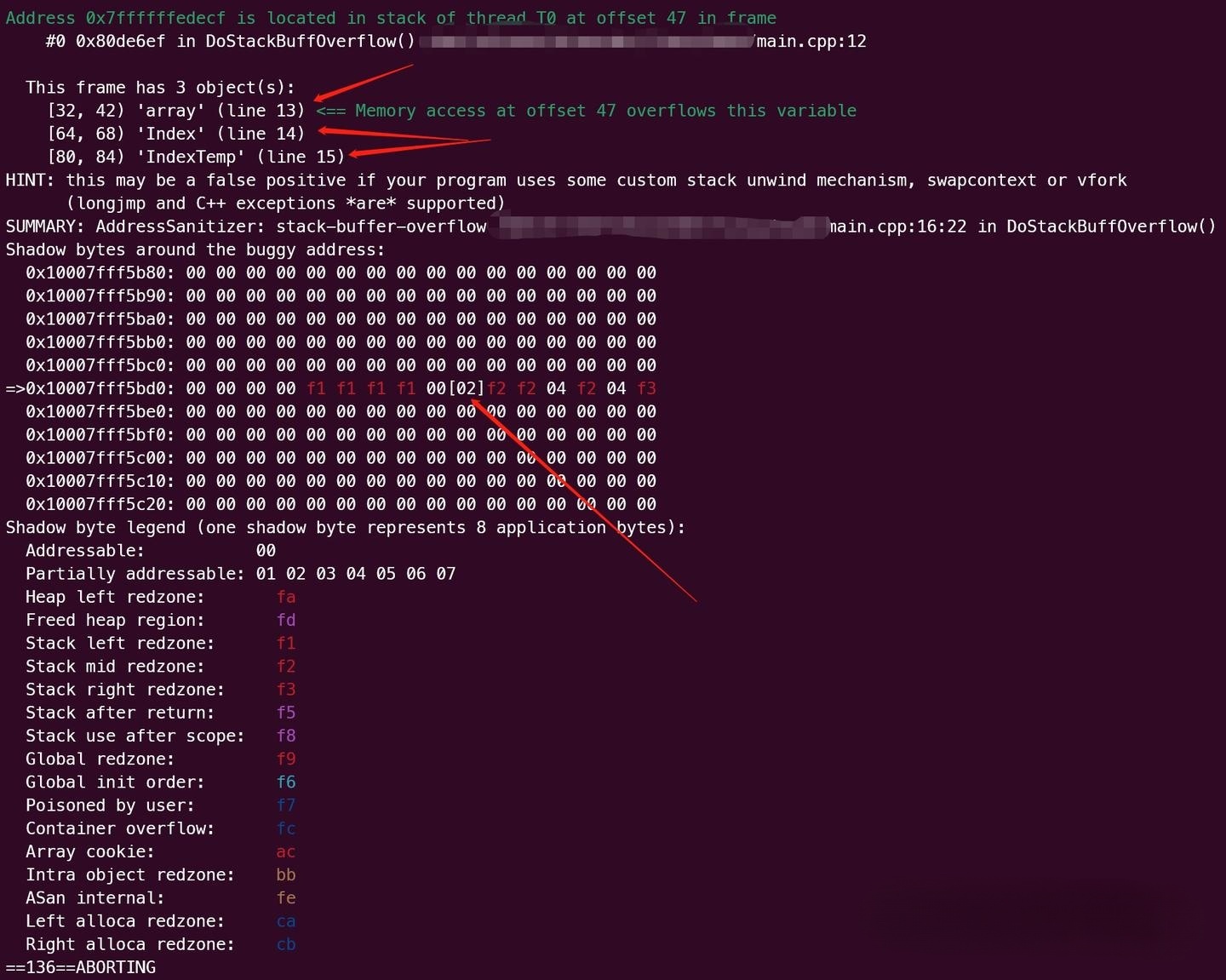
内存区域那块的红色字符比如 f1、f2 在截图下方的列表中可以查到是 Stack left redzone 和 Stack mid redzone,这意味着 Asan 发现了一个涉嫌访问栈区非法内存相关的错误。
参考文献
附录:面经小问答
gdb 调试的时候,出现很多问号,怎么进行调试
堆栈信息显示 ??? 意味着调试信息缺失,该开 -g 选项了。
调试过多线程吗?遇到死锁是怎么解决的?
假装自己调试 B+ 树的 Crabbing 协议的时候用到过,实际上在这个问题上只需要打一堆 log 就能推测出来了,打印 log 这个方法除了超大型工程因为有几十个线程和不计其数的 log 导致 log 几乎不可阅读、以及某些场景打印 log 就不触发死锁,不打印就触发死锁之外,基本上是调试死锁的首选。
参考GDB 多线程调试小连招自行准备话术。举例有:
Faker 话术
我用过 gdb,比如调试正在运行的程序,先用 ps -ef 获取 pid,然后使用 gdb attach pid。
调试多线程,我会先 list 看看在哪行源码,或者在那个 C++ 文件,break 可以 xxx.cpp:30,在某个文件上第 30 行打个断点,然后 run 跑起来,info thread 左上角的星号是正在执行的线程,可以用 thread id 来切换线程,还可以用 set scheduler-locking 来设置只让一根线程执行。
怎么分析 core dump?
先用 ulimit -c unlimited 确保 core 文件生成,然后gdb your_exe core加载。用bt full直接看崩溃堆栈,发现是野指针*ptr = 7越界了。再结合info registers看寄存器状态,确认无效地址。最后用watch ptr设观察点。
附录:GDB 基础命令
| 命令 | 描述 | 示例 |
|---|---|---|
break |
在函数入口/指定文件行设置[条件]断点 | break main |
continue (c) |
继续执行到下一个断点 | c |
next (n) |
单步执行(不进入函数) | n |
step (s) |
单步执行(进入函数) | s |
bt / backtrace |
打印当前堆栈 | bt |
info registers |
查看寄存器状态(定位崩溃指令) | info registers |
print <变量名> |
查看变量值,可以直接打印表达式 | print x |
x/<格式> <地址> |
查看内存内容(如十六进制) | x/10x 0x123456 |
附录:GDB 调试原理 🧠
这个背一下倒是无妨,毕竟 ptrace 函数和 INT 3 指令也不难记。
GDB 调试原理分为两部分:
- 为什么能看到其他进程的汇编代码
- 断点是怎么工作的
为什么能看到其他进程的汇编代码
GDB 能够对程序进行调试,源自于一个系统调用:ptrace
1 |
|
第一个 enum 参数 request 指定了要使用 ptrace 的什么功能。
使用 GDB 启动程序(调试小程序常用)
原理就是开启一个 GDB 进程,然后 GDB 进程 fork 出一个子进程,让子进程执行 PTRACE_TRACEME,然后子进程再调用 execve()。
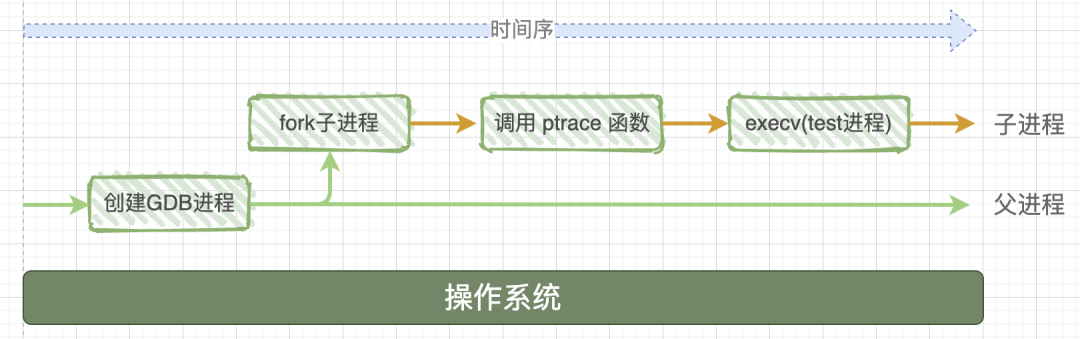
ptrace 是一个系统调用,允许一个进程(通常是调试器)观察和控制另一个进程(被调试的程序)。它提供了多种操作模式,包括但不限于:
- PTRACE_TRACEME:告诉内核当前进程希望其父进程作为调试器进行跟踪。顾名思义,就是“跟踪我”,通常由子进程调用。
- PTRACE_PEEKTEXT/PEEKDATA:读取被跟踪进程内存中的数据。
- PTRACE_POKETEXT/POKEDATA:向被跟踪进程的内存中写入数据。
- PTRACE_CONT:继续执行被跟踪的进程直到下一个信号发生。
- PTRACE_SYSCALL:继续运行,但在下一次进入或退出系统调用时停止。
- 还有其他许多命令用于设置断点、获取寄存器状态等。
当使用 GDB 调试程序时,首先会创建一个新的子进程,并让这个子进程调用 ptrace(PTRACE_TRACEME, ...) 来表明自己愿意被父进程(即 GDB)追踪。之后,每当子进程接收到任何信号(包括由于异常而产生的信号),内核都会暂停子进程并将控制权交给父进程(GDB),以便它可以检查子进程的状态或者修改其行为。
execve 系统调用用于执行一个新程序。具体来说,它会加载指定的可执行文件及其参数到当前进程的地址空间中,并开始执行该程序。如果成功,原始程序将不再运行;如果失败,则返回错误信息给调用者。
在 GDB 调试场景下,一旦子进程调用了 ptrace(PTRACE_TRACEME, ...) 并准备就绪后,接下来就会调用 execve 来启动实际要调试的目标程序。此时,因为之前已经设置了 PTRACE_TRACEME,所以每当目标程序遇到事件(如断点、异常等)时,都会触发内核暂停该程序,并通知 GDB,使得 GDB 能够接管控制并进行相应的调试操作。
使用 GDB attach 程序(调试大程序只能用这个)
对于启动流程超级长且启动流程与待调试区域无关的程序,使用 gdb 直接运行甚至不一定能运行成功。这时就只能使用 gdb attach PID。
这时 ptrace 第一个参数传入的就是 PTRACE_ATTACH,也就是 GDB 进程调用来 attach 到已经运行的子进程中。这个命令会有权限的检查,比如普通用户进程不能 attach 到 root 进程中。
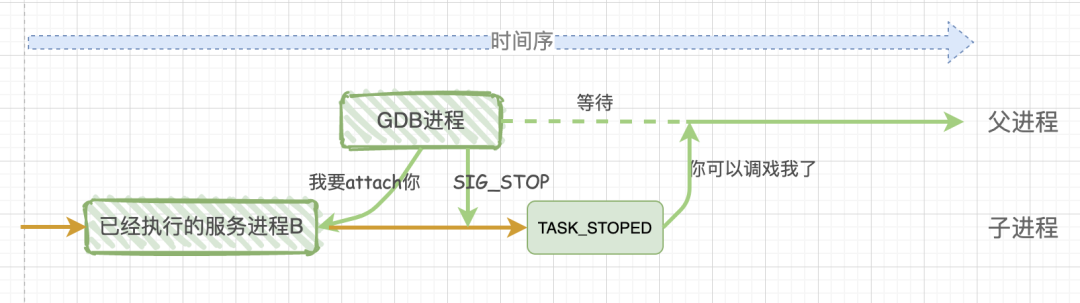
流程是:
- 运行一个 GDB 进程,调用 ptrace() 尝试去 attach 附着目标进程 test
- 此时 GDB 需要给 test 进程发送一个信号 SIGSTOP,要求 test 停止,这个信号是不能忽略的
- test 进程就进入 TASK_STOPED 状态,(用 top -u 用户名可以看到被 gdb attach 的进程如果没有 continue 的话,其进程状态是 t,这个就是暂停或被跟踪),然后之后状态是被跟踪状态 TASK_TRACED,这个不重要,反正状态都是 t,而不是 Run。
断点是怎么工作的
1. 替换指令为 INT 3
- 在源码某一行设置断点时,GDB 会找到该行对应的机器指令地址。
- GDB 使用
ptrace(PTRACE_PEEKTEXT)读取原始指令,并保存到内部的 断点链表(Breakpoint List) 中。 - 然后使用
ptrace(PTRACE_POKETEXT)将该地址处的第一个字节替换为0xCC(即INT 3指令)。
1 | 原指令:mov eax, 1 --> 0xB8 01 00 00 00 |
注意:x86/x64 架构中,
INT 3是一个单字节指令,非常适合用来做断点插入。
BTW,这个是软中断,硬中断是外设给 CPU 中断。
类型 实现方式 特点 软件断点 替换指令为 INT 3最常用,无数量限制,但会修改代码段 硬件断点 利用 CPU 寄存器(DR0~DR7) 不修改代码,速度快,但数量有限(通常最多 4 个) GDB 默认使用的是软件断点,除非特别指定使用硬件断点(如
hbreak命令)。
2. 执行到断点时触发中断
- 程序正常运行,直到遇到
INT 3指令。 - CPU 执行
INT 3后会触发 中断处理程序,内核识别到这是一个调试中断。 - 内核暂停当前进程(发送
SIGTRAP信号),并将控制权交给 GDB(因为进程已经被 ptrace 跟踪)。
3. GDB 接收到 SIGTRAP 并处理断点
- GDB 收到
SIGTRAP信号,知道程序在某个断点处被中断。 - GDB 查询当前 PC 指针的位置,查找是否是我们之前插入的断点地址。
- 如果是,则:
- GDB 把 PC 指针回退一步(因为
INT 3已经执行了一条指令)。 - GDB 把原来的指令写回去(从断点链表中取出)。
- GDB 进入交互模式,允许用户查看寄存器、内存、变量等信息。
- GDB 把 PC 指针回退一步(因为
4. 单步执行一次原始指令
- 用户输入
continue或step后,GDB 会临时恢复原始指令,然后使用ptrace(PTRACE_SINGLESTEP)单步执行一次这条指令。 - 执行完成后,GDB 又会重新插入
INT 3指令,以便下次再次命中这个断点。
GDB 整体调用流程(以 GDB 启动程序为例)
- 调试器(如 GDB)创建一个子进程。
- 子进程调用
ptrace(PTRACE_TRACEME)表明自己愿意被调试。 - 子进程接着调用
execve加载并开始执行目标程序。 - 在目标程序执行过程中发生的任何事件(例如断点、异常)都会导致内核暂停目标程序,并通知调试器(GDB)。
- GDB 可以根据需要采取行动,比如单步执行、查看变量值等,然后决定是否继续执行目标程序。
参考文献
附录:ASan 检测原理
为什么两个工具都有原理部分?因为笔者广罗面经,都看到有面试官问了。原理懂了用法也懂了,这下要成真高手了:(
What can I say?
两个主要实现技术点:
- 内存操作进行插桩:对
new/malloc/delete/free/memcpy等其它内存访问操作进行编译时替换与代码插入,由编译器自动完成的 - 内存映射与诊断:按照一定的算法对原始内存进行一分影子内存的拷贝生成,目前不是 1:1 的拷贝,而是巧妙的按 1/8 大小进行处理,并进行一定的下毒与标记,减少内存的浪费。正常访问内存前,先对影子内存进行检查访问,如果发现数据不对,就进行诊断报错处理
ASan 弊端:
ASan 也不是完美的,不过它在 Chrome 与 Android 上是有使用的,据说诊断出几十处问题了。但也有一些弊端吧:
- 对内存溢出检查:依赖正常内存左右两端设定毒药区域大小;比如 128 字节,虽然这个值可以调,但越界超出这个值后,依然无法检查的到
- 释放后访问检查:目前是对该内存进行隔离,并对影子内存标记为 0xFD,但这个隔离不可能永久;一但被重新复用后,也可能造成严重内存问题,有类像内存池复用崩溃问题
- 性能问题:由于插桩引入了很多汇编指令(Andorid 平台还会有动态库),性能与内存上对比其它产品虽然还可以,但也只能在内部环境或 Debug 环境部署,无法直接应用到线上